P Is An Estimator Of P
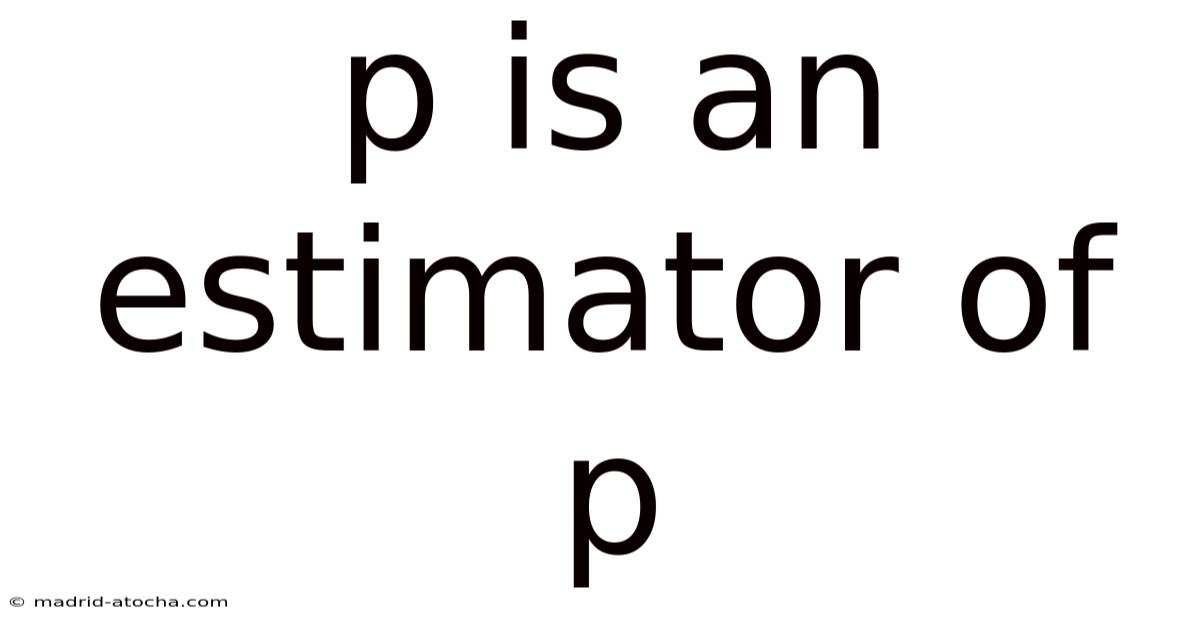
In the realm of statistics and data science, one of the most fundamental tasks is to learn about a large group—a population—by studying a smaller, manageable subset known as a sample. A core question that arises is: how do we bridge the gap between what we observe in our sample and the unknown truth about the entire population? The answer lies in the use of estimators. The statement “p is an estimator of p”, while seemingly tautological, points to a crucial conceptual distinction when we interpret the symbols correctly. In standard statistical notation, p (often read as “p-hat”) is the sample proportion, a value calculated from your collected data. This p serves as the estimator for the true, unknown population proportion, which is also denoted by p. This article will unpack this essential relationship, exploring why the sample proportion is our primary tool for estimating the population proportion, the mathematical properties that make it trustworthy, and the critical thinking required to use it effectively.
Understanding the Core Duo: Population Proportion (p) vs. Sample Proportion (p̂)
Before diving into estimation, we must solidify our definitions. The population proportion (p) is a fixed, but almost always unknown, number. It represents the true percentage or fraction of a specific characteristic within an entire population of interest. For example, p could be the true proportion of all voters in a country who support a particular policy, the actual fraction of defective items in a factory's entire production line, or the real percentage of a certain species of bird in a vast forest. Because measuring every single member of a population is frequently impossible, prohibitively expensive, or destructive, p remains a mystery we seek to uncover.
The sample proportion (p̂), on the other hand, is a known, calculated value. It is derived directly from a randomly selected sample from that population. If we take a sample of size n and count the number of individuals in the sample that possess the characteristic of interest (let’s call that count x), then: p̂ = x / n This p̂ is our point estimate—our best single guess—for the elusive population parameter p. The statement “p is an estimator of p” is shorthand for “the random variable p̂ is an estimator of the fixed parameter p.” The estimator (p̂) is the rule or formula we apply to any possible sample. The specific number we get from our one sample is the estimate. This distinction is vital: p̂ is the estimator (a function of the sample data), and a realized value like 0.47 is an estimate.
Why p̂ is the Natural and Logical Estimator for p
The sample proportion is not just an estimator; it is the most intuitive and widely used one for a population proportion. Its logic is beautifully simple: if you want to guess the overall fraction, look at the fraction you observed in your representative slice. If 42 out of 100 randomly sampled adults own a electric vehicle (p̂ = 0.42), it is perfectly reasonable to estimate that approximately 42% of all adults do.
This reasonableness is formalized through a key property: unbiasedness. An estimator is unbiased if, on average over infinitely many repeated samples of the same size from the same population, it hits the true parameter value. The expected value (or long-run average) of the sampling distribution of p̂ is exactly equal to p. E(p̂) = p This means p̂ does not systematically overestimate or underestimate p. It is a fair, centered estimator. If you were to take hundreds of different random samples and calculate p̂ for each, the mean of all those p̂ values would converge to the true p. This property makes p̂ a fundamentally sound choice. Other estimators might be biased, meaning they consistently drift high or low, making them less reliable for honest inference.
The Behavior of p̂: Sampling Variability and Distribution
While unbiased, a single p̂ from one sample will almost never equal p exactly. This discrepancy is due to sampling variability—the natural randomness inherent in selecting different samples. Understanding the behavior of p̂ across all possible samples is critical. Its distribution, called the sampling distribution of p̂, has well-defined characteristics governed by the population proportion p and the sample size n.
- Shape: When the sample size is sufficiently large (a common rule is that both n·p and n·(1-p) are at least 10), the sampling distribution of p̂ is approximately normal (bell-shaped). This is a consequence of the Central Limit Theorem applied to proportions.
- Center: As established, the mean of the sampling distribution is p.
- Spread: The standard deviation of this distribution, called the standard error of p̂, quantifies the typical amount p̂ deviates from p due to random chance. It is calculated as: SE(p̂) = √[ p(1-p) / n ] This formula reveals two powerful levers: as the sample size n increases, the standard error decreases, meaning p̂ becomes
more precise. Conversely, as the population proportion p approaches 0 or 1, the standard error also increases, reflecting a greater degree of uncertainty.
Confidence Intervals: Quantifying Our Uncertainty
Because p̂ is an estimate, and estimates are subject to variability, we don’t simply state “approximately 42% of adults own an electric vehicle.” Instead, we construct a confidence interval to express the plausible range of values for the true population proportion. A 95% confidence interval, for example, means that if we were to repeat the sampling process many times and construct a confidence interval each time, approximately 95% of those intervals would contain the true population proportion.
The formula for a confidence interval for a population proportion is:
p̂ ± z*SE(p̂)
Where:
- p̂ is the sample proportion.
- z* is the z-score corresponding to the desired confidence level (e.g., for a 95% confidence interval, z* = 1.96).
- SE(p̂) is the standard error of the sample proportion.
Using the previous example (p̂ = 0.42, SE(p̂) ≈ 0.04), a 95% confidence interval would be 0.42 ± 1.96 * 0.04, which is approximately 0.34 to 0.46. This tells us that we are 95% confident that the true proportion of adults who own an electric vehicle lies between 34% and 46%.
Beyond the Basics: Considerations and Limitations
While p̂ is a robust and widely applicable estimator, it’s crucial to acknowledge its limitations. The accuracy of p̂ hinges on the sample size; small samples can lead to unreliable estimates. Furthermore, the assumption of random sampling is paramount. Bias introduced through non-random sampling methods will invalidate the results. Finally, the normal approximation to the sampling distribution of p̂ only holds when n is sufficiently large, as previously discussed.
Despite these considerations, the sample proportion remains a cornerstone of statistical inference, providing a practical and intuitive way to estimate population parameters and quantify uncertainty. Its unbiasedness, combined with the readily calculable standard error, allows us to construct meaningful confidence intervals and draw informed conclusions about the world around us.
In conclusion, the sample proportion (p̂) is a fundamentally sound estimator for a population proportion due to its unbiasedness and the predictable behavior of its sampling distribution. By understanding its properties, particularly the influence of sample size and the concept of confidence intervals, we can effectively utilize p̂ to make reasonable inferences and quantify the uncertainty inherent in any statistical estimate. It’s a powerful tool, best employed with a clear awareness of its underlying assumptions and potential limitations.
Latest Posts
Latest Posts
-
Which Manager Is Exhibiting Informational Power
Mar 21, 2026
-
Correctly Complete This Sentence Using The Words Provided
Mar 21, 2026
-
What Hormone Can The Ergogenic A Caffeine Help To Stimulate
Mar 21, 2026
-
What Type Of Mechanism Step Is Shown Below
Mar 21, 2026
-
Correctly Label The Following Parts Of A Renal Corpuscle
Mar 21, 2026